// RESULTS
Resultado no lote de teste
Medido localmente com 8 recibos sintéticos, rodando em CPU única, sem GPU e sem nenhuma API paga:
100%
acerto em fornecedor, data, nº do documento e total
100%
reconciliação item a item com o total extraído
~7.100
documentos/hora em CPU única
~57k
documentos/hora com 8 workers em paralelo
Os números acima são de um benchmark local sobre este protótipo de demonstração — não uma carga de produção real. Ainda assim, já superam com folga a marca de 1.000 documentos/hora mesmo sem paralelização, o que mostra que a arquitetura escala horizontalmente sem depender de APIs pagas.
Entrada
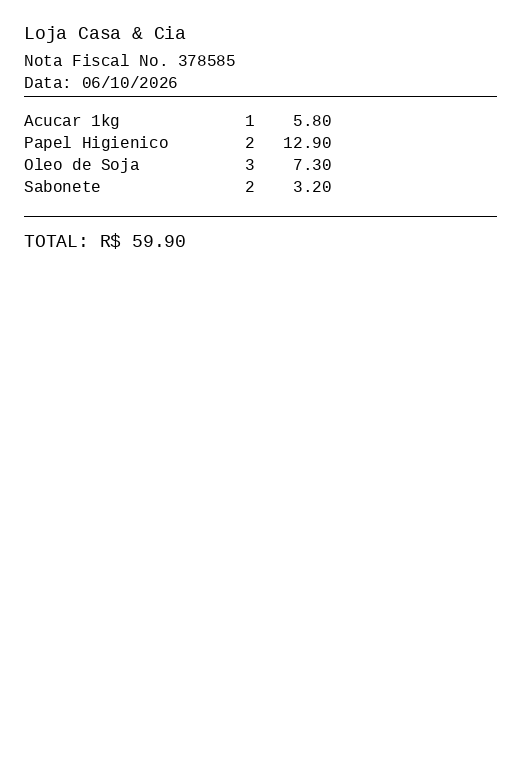
Saída estruturada
{
"vendor": "Loja Casa & Cia",
"date": "06/10/2026",
"invoice_number": "378585",
"items": [
{ "description": "Acucar 1kg", "qty": 1, "unit_price": 5.8 },
{ "description": "Papel Higienico", "qty": 2, "unit_price": 12.9 },
{ "description": "Oleo de Soja", "qty": 3, "unit_price": 7.3 },
{ "description": "Sabonete", "qty": 2, "unit_price": 3.2 }
],
"total": 59.9
}
Tecnologias
* adaptador pronto na arquitetura, ativado com uma chave de API